
tg-me.com/knowledge_accumulator/35
Last Update:
MuZero [2020] - AlphaZero выходит из плена настольных игр
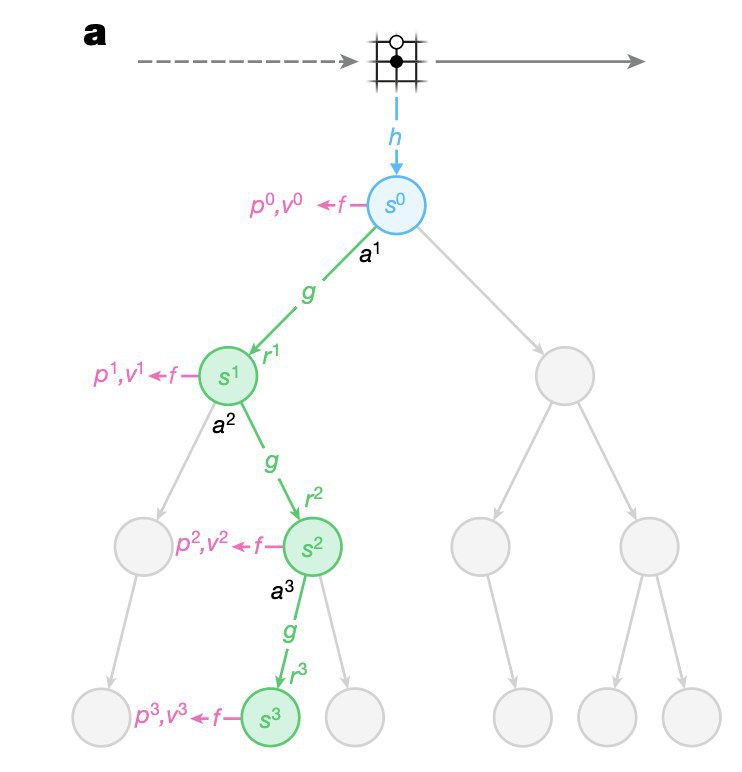
Попытка моделировать динамику среды (то, какими состояние и награда у среды будут следующими, если знаем текущее состояние и действие агента) - это отдельная песня в рамках RL, которая обычно не даёт такого профита, который позволяет компенсировать сложность подхода. Всё потому, что генерировать состояния слишком трудно из-за неопределённости в среде и высокой размерности состояния.
Тем не менее, в рамках MuZero пытаются применить подход к выбору действий с помощью планирования, как в AlphaZero, в ситуации, когда доступа к модели среды нет.
Что делают с проблемой сложности среды? Оказывается, можно просто забить на состояния, и при обучении своей модели динамики среды пытаться предсказывать только будущие награды и действия нашей стратегии. Ведь чтобы их предсказывать, нужно извлечь всё самое полезное из динамики и не более. Удивительно, но это работает! Более того, эта система может играть в Го на уровне AlphaZero, у которой доступ к модели есть.
Я думаю, что отказ от попытки предсказывать будущее состояние это верно, потому что убирает ненужную сложность. От этого отказались в RND, NGU, в MuZero и не только.
Глобально говоря, от этого имеет смысл отказываться всегда, когда генерация не является самоцелью. И я думаю, что это рано или поздно будут делать во всех доменах, даже в текстах.
@knowledge_accumulator
BY Knowledge Accumulator
Share with your friend now:
tg-me.com/knowledge_accumulator/35